Introduction to SCGI Inventory
Version
This is version 1.0.0 of the SGCI Resource Description Specification schema. This work is released under an Apache 2.0 license .
Introduction
The user-facing components of the Cyberinfrastructure (CI) ecosystem, science gateways and scientific workflow systems, share a common need of interfacing with physical resources (storage systems and execution environments) to manage data and execute codes (applications).
However, there is no uniform, platform-independent way to describe either the resources or the applications. To address this, we propose uniform semantics for describing resources and applications that will be relevant to a diverse set of stakeholders.
The SGCI Resource Description Specification provides a standard way for institutions and service providers to describe storage and computing infrastructure broadly available to the research computing and science gateway community. SGCI Resource descriptions provide a foundation for interoperability across gateway components and other cyberinfrastructure software.
The current, initial version of the resource description language focuses on “traditional” HPC and high-throughput storage and computing resources
Definitions
Definitions of terms used in the specification will be added here.
Specification Format
SGCI resource descriptions are JSON documents that conform to the JSONSchema definition describing a particular version of the SGCI Resource Description Specification.
Examples
We illustrate the main features of the specification by walking through a few prototypical examples.
SCIGAP Development Storage
A server or virtual machine providing storage accessible over SSH can be registered as resource with a single object
provided within the "storageResources" attribute describing the connection information and the file systems present.
In the SGCI Resource Descriptions specification, it is assumed that all resources provide some kind of storage
capability; that is, at least one object within the storageResources array attribute must be provided, and within
that object, at least one connections object must be provided.
A fundamental principle in the SGCI Resource Description Specification is that the host attribute uniquely
identifies a resource, and only one description document for a given host can exist in the inventory. The value of
host is a network addressable identifier for the resource, most typically, a fully qualified domain name.
The following example describes a hypothetical storage resource used by the SCIGAP framework in its development environment.
{
"schemaVersion": "1.0.0",
"name": "SCIGAP Development Storage",
"host": "pgadev.scigap.org",
"description": "POSIX storage server for the SCIGAP development environment.",
"storageResources": [{
"storageType": "POSIX",
"connections": [{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
}],
"fileSystems":
[{
"rootDir": "/"
}]
}]
}
Corral Storage System at TACC
The Corral storage system at TACC provides a more complicated example, with multiple file systems mounted onto a single resource and multiple types of storage endpoints available. The following example illustrates how a system like Corral, with many storage functionalities, can be described in a single document using the specification.
{
"schemaVersion": "1.0.0",
"host": "data.tacc.utexas.edu",
"name": "tacc-corral-storage-login",
"description": "TACC Corral high-performance storage resource",
"storageResources": [
{
"storageType": "POSIX",
"connections": [
{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
},
{
"connectionProtocol": "SSH",
"securityProtocol": "PASSWORDS",
"port": 22
},
{
"connectionProtocol": "SCP",
"securityProtocol": "SSHKEYS",
"port": 22
},
{
"connectionProtocol": "SCP",
"securityProtocol": "PASSWORDS",
"port": 22
},
{
"connectionProtocol": "SFTP",
"securityProtocol": "SSHKEYS",
"port": 22
},
{
"connectionProtocol": "SFTP",
"securityProtocol": "PASSWORDS",
"port": 22
}
],
"fileSystems": [
{
"mountDir": "/home",
"capacity": {
"totalBytes": 940686700544
}
},
{
"mountDir": "/work",
"capacity": {
"totalBytes": 20401094843136000
}
}
]
},
{
"storageType": "S3",
"connections": [
{
"connectionProtocol": "HTTPS",
"securityProtocol": "APIKEYS"
}
],
"fileSystems": []
},
{
"storageType": "IRODS",
"connections": [
{
"connectionProtocol": "IRODS",
"securityProtocol": "PASSWORDS"
}
],
"fileSystems": []
}
]
}
Carbonate HPC
Compute capabilities provided by resources are described within one or more computeResources definitions. Unlike the
storageResources attribute that must contain at least one object, the computeResources attribute is entirely
optional. Each compute resource object must define at least one connections object, analogous to the storageResource
definitions. Additionally, each compute resource defines the way workloads are scheduled on the resource using the
schedulerType property, with values such as FORK or BATCH. The value of schedulerType dictates additional
objects that may be provided, such as the batchSystem object for value BATCH.
Carbonate is Indiana University’s large-memory computer cluster. The simple description below only includes the BATCH
submission capability and does not provide any partion (queue) information.
{
"schemaVersion": "1.0.0",
"name": "Carbonate HPC",
"host": "carbonate.uits.iu.edu",
"computeResources": [{
"schedulerType": "BATCH",
"connections": [{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
}],
"batchSystem": {
"jobManager": "SLURM",
"commandPaths": [{
"name": "SUBMISSION",
"path": "/foo"
}]
}
}],
"storageResources": [{
"storageType": "POSIX",
"connections": [{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
}],
"fileSystems": [{
"rootDir": "/",
"scratchDir": "/scratch"
}]
}]
}
TACC Stampede2 Cluster
In the final example describing the TACC Stampede2 supercomputer, two computeResources definitions are included,
one with schedulerType having value BATCH and one with schedulerType having value FORK.
While all “real” workloads are required to be submitted to the
batch scheduler, the FORK scheduler could be utilized for “code compilation” tasks that run
directly on the login node. Additionally, the BATCH compute resource includes descriptions of the partitions
(queues). These are optional but very valuable for science gateway projects.
{
"schemaVersion": "1.0.0",
"host": "stampede2.tacc.xsede.org",
"name": "tacc-xsede-stampede2",
"description": "WIP: Sample resource for TACC Stampede2 Cluster",
"computeResources": [
{
"schedulerType": "BATCH",
"connections": [
{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
},
{
"connectionProtocol": "SSH",
"securityProtocol": "PASSWORDS",
"port": 22
}
],
"batchSystem": {
"jobManager": "SLURM",
"commandPaths": [
{
"name": "SUBMISSION",
"path": "/bin/sbatch"
}
],
"partitions": [
{
"name": "normal",
"totalNodes": 256,
"nodeHardware": {
"cpuType": "KNL CPUs @ 1.40GHz",
"cpuCount": 68,
"memoryType": "DDR4",
"memorySize": "96 GB"
}
}
],
"executionCommands" : [
{
"commandType" : "mpi",
"commandPrefix" : "ibrun",
"moduleDependencies" : ["intel/17.0.4", "impi/17.0.3"]
}
]
}
},
{
"schedulerType": "FORK",
"connections": [
{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
},
{
"connectionProtocol": "SSH",
"securityProtocol": "PASSWORDS",
"port": 22
}
],
"forkSystem": {
"systemType": "LINUX"
}
}
],
"storageResources": [
{
"storageType": "POSIX",
"connections": [
{
"connectionProtocol": "SSH",
"securityProtocol": "SSHKEYS",
"port": 22
}
],
"fileSystems": [
{
"homeDir": "/home1",
"scratchDir": "/scratch",
"workDir": "/work"
}
]
}
]
}
Information Not In The Spec
Over the course of working on the specification, the project has decided to not include different resource types and/or additional attributes of existing resource types in version 1.0 for various reasons. In some cases, we plan to include the information in a subsequent version of the specification. In this section we collect some of the information not chosen for v 1.0, together with the rationale for not including it.
Multi-factor authentication (MFA) requirements of a resource – MFA requirements are definitely important to capture and will be included in a subsequent version of the spec, but we want to make sure we have a good, general-purpose way of describing what seem to be a rapidly evolving aspect of cyberinfrastructure.
Available Software Modules and other software on an execution system – The project may include such information in a subsequent version of the spec, but we want to make sure we have good mechanisms in place for working with information that is changing rapidly.
More recent cloud storage and computing resource types – A number of different cloud resource types, including container orchestration systems such as Kubernetes and Docker Swarm, as well as Functions-as-a-service such as AWS Lambda, were intentionally not included in version 1.0. We hope to include these in a future release once the community has built some expertise incorporating them into science gateways.
Databases and Web Services – Databases, including MySQL, Postgres, MongoDB, etc., and web service APIs like Figshare, Google Drive, etc., are not included in the spec, as these represent a significant departure from the kinds of resources defined in the current version. We do not currently plan to include them in any future version.
Integration
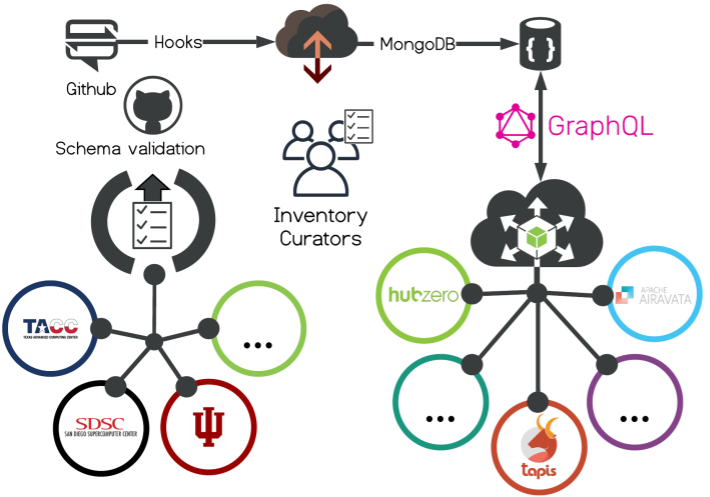
The SCGI Inventory is currently been integrated with Airavata, HUBzero ® , and Tapis. We expect the inventory to be adapted by others soon.
Links:
https://github.com/SGCI/sgci-resource-inventory
https://github.com/SGCI/sgci-resource-inventory-cache-service
Get Involved!
Issues, Comments, PRs all welcome!
SGCI: help@sciencegateways.org
Email: jstubbs at tacc.utexas.edu, smarru at iu.edu, dmejiapa at purdue.edu